NBA Player Embiidings
Leveraging Deep NN Embeddings to Augment Coaching and Identify True Offense/Defense
December 28, 2019
- Propose and demonstrate novel use of neural network embeddings (aka "Embiidings") to measure offensive and defensive capabilities of NBA players
- Visual demonstration of Embiidings both individually and additively (e.g., Lebron vs Draymond) speaks to this approach's ability to objectively measure player's capabilities
- Benefits include enhancement of coaching strategies (e.g., player matchups, recruiting potential talent) and the capability to quantitatively measure some end-of-year awards for the first time (e.g., Defensive Player of the Year)
- Discussion of merit to open sourcing more quality NBA data to unlock community engagement and further advance the NBA analytics field
- (Update 2/28/21) Formalized white paper*: LINK

While most of my hometown state of Texas adored (American) football growing up, my sports love was far and away basketball. Coming into sentience during the final peak years of his Airness, the seed in my heart for the game (to me, the game will always refer to basketball) continued to bloom over the years as the sport grew into the global phenomenon it is today.
So, with the NBA season back in full swing, analyzing the best game in the world (in my biased unbiased opinion) was top of mind. Conveniently, at the start of every NBA season, me and a group of friends engage in gentlemanly wagers for which teams will have the best reputation by the end of the season. So, I thought, why not try and augment this year's predictions with a bit of data?
The project's origins thus began with a quick and dirty time series model that took prior year records to predict the following season’s records. Unfortunately, the predictions didn’t have much alpha over existing public models and suffered from many of the problems also experienced by FiveThirtyEight in their own early ELO models. So, focus switched to a more micro level - measuring and predicting the impact a player has on a game regardless of the team while accounting for playing composition. In other words, rather than build a model from the top down, let’s build a model from the bottom up.
This signal is especially important to capture given all the trades that happen in the offseason (e.g., AD, Kyrie, KD, Kawhi, Russell Westbrook, Jimmy Butler this year alone) and will undoubtedly happen in the upcoming trade window(s). Rather than approach this from a nearest neighbor model + Monte Carlo simulations like FiveThirtyEight, I landed on the hypothesis that a deep neural embedding would be even more valuable in capturing the many semantics of a player not available in the typical stat sheet.
For those familiar with NLP, this would be like how word embeddings offered so much more value versus prior state of the art one-hot encodings. There was some prior art on creating deep embeddings but narrowly scoped for shot selection, which served as a reasonable foundation with which to construct more generalizable "Player Embiidings."
So, What are the Benefits of These Embiidings?
Everyone’s heard an announcer/coach/player say that stats can’t fully measure a player. Draymond himself was an enigma in the league for the longest time where new stats had to be developed to capture his impact on the floor. However, it’s the development of such new measurements (along with improved data capture, ease of data analysis/transformation/storage at scale, more sophisticated statistical interest in the game, and machine learning breakthroughs) that give me confidence in the ability of basketball “quants” to offer more value by augmenting the capabilities of the front office and coaching staff.
I contest Player Embiidings, aka the player embeddings proposed by this research, are one of the techniques that have the potential to push the field and raise it to the next level.
Why do Player Embiidings matter? What is their use? To answer these questions, I’ve outlined a few examples below.
-
Player Embiidings can be used to enhance scouting efforts. Consider that a team suffers an injury midseason to a key player (or multiple as is the case with the current Trail Blazers and their "big men"), and they need to fill the minutes with a player who is most similar to the one that's been injured. In this case, a nearest-neighbor search in the embedding space can uncover the candidates who will be able to plug and play to fill the gap without the expensive maneuver of adjusting the team’s strategy midseason. In addition to (and even as a replacement of) stat sheets, a team's front office could use Player Embiidings to automate more of their scouting efforts and widen the total pool of candidates they consider at the top of the funnel. This opens up opportunities to arbitrage the market by finding undervalued player assets, enhance existing quantitative measures of players, and improve the efficiency / lower the costs of scouting.
-
More Accurate Measure of True Defense / Offense. A common story line is how current mainstream stats fail to capture the impact certain players have on the game - Draymond Green knows this well. With a Player Embiiding, true offense and defense can actually be approximated in multidimensional space. As an example of how Player Embiidings could enhance this process, we could compare how Kawhi Leonard's defense of a player compares to the average defender by measuring the impact he has on the probability of a point being scored. More importantly, we can play with many levers in this example such as 1) switching Kawhi for any other player to measure who's ankles are being absolutely broken by a particular shooter or 2) using the average defender and then switching out the offensive player to measure who is the most cold-blooded offensive assassin. In addition, current shot charts do not account for situational factors such as closeness of the nearest defender, shooter movement before the shot, and time on the clock. Augmented by a Player Embiiding, the below findings show a situational shot chart can now be dynamically generated moment by moment or leveraged from a historical perspective to analyze which player was more “clutch”, an offensive machine, etc.
-
Game Simulation and Strategy. Coaching staff can review historical plays in the context of Player Embiidings to advise what other approaches could have been considered for a higher percent of scoring in future occurrences. In cumulation over the 16,000+ field goals per game (defense + offense), these probability boosts could be the difference between making/missing the playoffs. These probabilities would be novel in that they are adjusted not just for the opposing team’s current positions but also WHO those defenders are. Building off the more accurate measure of true defense and offense above, the Player Embiidings can also be used to create advantageous matchups on offense and defense (all other factors equal). They can thus be used to arbitrage and identify new matchups.
Findings, the real reason you're here
Overall, despite the severe limitations in data quality (covered in the Limitations section), the model is able to generate reasonable Player Embiidings that prove their novel feasibility and value in leveraging the vast void of the embedding hypersphere. Ultimately, these examples give confidence to the ability of this technique to aid professional franchises and NBA statisticians in arbitraging strategy and player comparisons if significantly more data was available. A few are outlined below:
True Player Impact and Strategic Matchups
First and foremost, Player Embiidings can be used as a more accurate measure of the impact a player has to the game. Armed with the trained embeddings and slight tweaks to the input format of the model, a shot probability heatmap can be outputted that adjusts for the time on the shot clock, shooter, defender, distance between the shooter/defender, and the location of the shot. This enables multiple in-depth analyses of true impact including 1) expectations for the average NBA player on offense/defense 2) outperformance of a particular player versus the average 3) "clutch" ability and 4) the best and worst matchups.
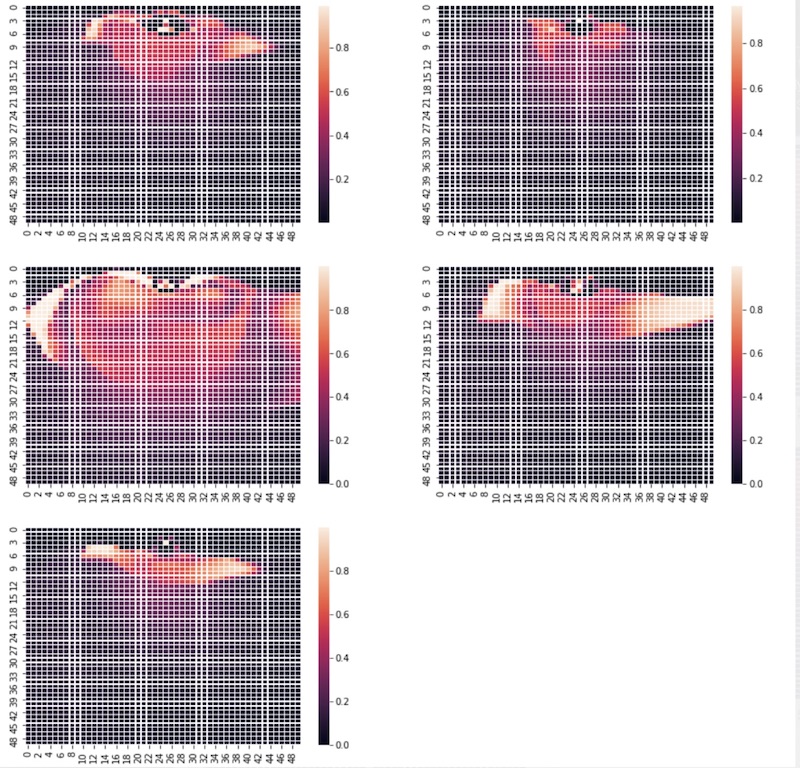
In the above chart, I’ve outlined a few examples:
- Top Left: Average Shooter Versus the Average Defender Across the NBA, the embeddings show the average player tends to be more efficient in the paint / around the basket. No surprise here given not everyone is Steph Curry (spoiler).
- Top Right: Average Shooter Versus Draymond Green Validating his claim as a defensive MVP, the embeddings also show how players like Draymond are able to dramatically limit the ability of players to make shots. Note how the embedding probabilities dramatically lower when he is the nearest defender.
- Middle Left: Steph Curry Versus the Average Defender Validating another Warriors claim to greatness, the embeddings also reveal the monster range and high efficiency of Steph Curry far beyond the paint. If the average players' shot map was a spark, Steph’s is an inferno covering nearly the entire half court.
- Middle Right: LeBron James Versus the Average Defender He may take a relaxed pace during the regular season, but LeBron proves he is still a dominant force around the rim with the occasional jumper from the perimeter.
- Bottom Left: LeBron James Versus Draymond Green
- Even against LeBron, Draymond has such an outsized effect on shrinking the offensive ability of the opposing team
- Despite Draymond’s ability, LeBron remains a force as evidenced by this shot map compared to the top right one
- It’s matchups like these that underlie the strategic value of these embeddings, as evidenced by Draymond frequently guarding LeBron over the past few years.
Successful Identification of Similar Offensive / Defensive Performers
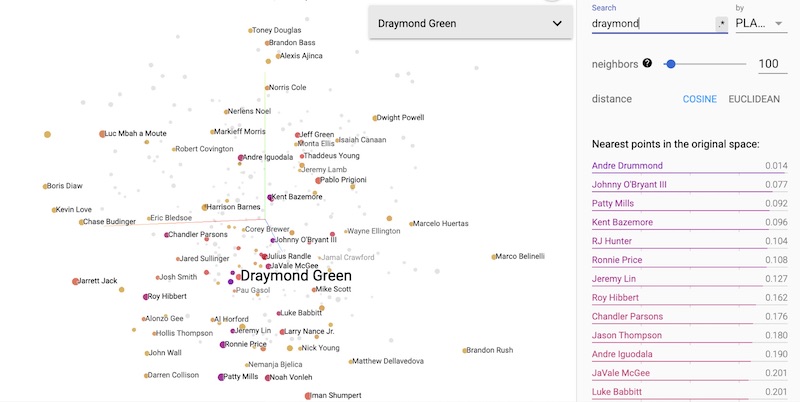
These embeddings can also be leveraged to identify similar caliber players and replacement opportunities via the clusters of players with similar impact to the game. In the first example of this, notice how Draymond Green and Andre Drummond are the closest players in terms of defensive style. This validates later pundits who started to take note of Andre Drummond’s defensive impact as being both top class and similar to Draymond’s (albeit, never quite at Draymond's level).
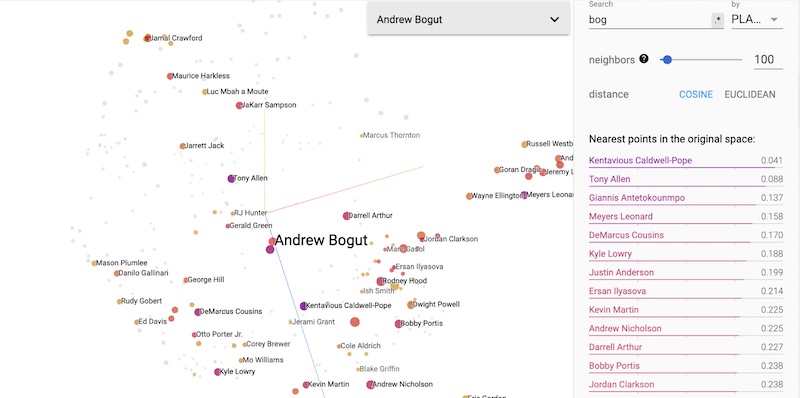
In the second example of this (also focused on the Warriors given not just their greatness but also proximity to where I lived at the time of the data), Andrew Bogut’s defensive embedding contains other well known centers such as Giannis who can put pressure in the paint but also have a decent perimeter defense game. Validating the use of embeddings as a front office tool, notice that one of Bogut’s future replacements, DeMarcus Cousins (for sadly all of ~8 playoff games), is also present on the list of nearest neighbors.
The Golden [Data] Hunt
For the curious of mind, how was the hunt for useful data to develop a Player Embiiding?
The holy grail would have been clean play-by-play data annotated for a player’s position, team, occurrence of the shot across time, and time-based labels for actions in the game (e.g., pass, block, assist, pump fake, etc). Basketball-Reference and NBA stats are both well known as high-quality open sources of data, but alas they were not quite open enough in this regard. Interestingly, NBA Stats does have a "Tracking Shots" dashboard for every player but provided no API or underlying datasource to scrape this data.
The first foray may have been a dead end, but it did provide leads which eventually led me down a Reddit rabbit hole. This time, rather than wondering where time went, I ended up coming across a few subreddits that analyzed and modeled play-by-play data in an exploratory manner (e.g., visualizations, shot generation, and even deep neural networks). Eventually, all signs pointed north to this repo which contained rich (relatively) play-by-play data at the origin of most other bodies of work.
While a breakthrough compared to other leads up to this point, I’d compare this moment to that of the American 49ers back in the day - panning for gold and having no idea whether the remaining rocks were gold, fool’s gold, or just plain rocks with no gold segments inside. From what could be immediately determined, the data was limited to half of the 2015/2016 season (the NBA apparently shut it down after various basketball quants released analyses), lacked official documentation / was often documented incorrectly by the open community, and was voluminous enough to the point that it was challenging to interact with or analyze at a high level out of the box.
It was the best available though and appeared sufficient, so the project made due and kicked gears into the next phase of the project - authenticating these gold nuggets (i.e., cleaning and transforming the data).
Authenticating the Data for Gold
It's a common refrain that 80% of data science is data preparation. That was absolutely true here as this became one of those projects where hours ensued understanding the layout of the data and then transforming -> joining -> filtering -> realizing the data annotations had mistakes -> adjusting -> repeating. I’ve spared others the cycles of blood, sweat, and tears, and have made all the code available on Github. Raw input data can be found in the original repo given its size.
The provided code transforms and filters the data from the 100+GB of uncompressed frame by frame play data recorded every 1/40th of a second composing 73 million frames of total play data to a few MB of data that have the exact frame when a shot is taken for each miss/make with every player’s exact position superimposed onto one half of a basketball court.
Be forewarned though that this data is still far from perfect which ends up impeding the following section. For instance:
- Shots/blocks/steals/possessions are not annotated in the data. As a result, assumptions have to be baked in and corroborated against official tracking sheets. A machine learning model could be built to annotate this data… except this is predicated on having a solid foundation of data for the model as we'll see below. Catch-22.
- The game clocks within the data often were misaligned with those of the actual game clocks. This leads to significant time lags/leads that make it impossible to determine which frame matches which shot as the lag/lead is variable across stadiums and even games. This ultimately filters out nearly 70% of the data in order to have confidence in the data the model will be trained on, and leads to sparse training data for many players. *(As an aside, I suspect this is also one of the biggest frustrations for NBA teams who consumed this data. They would review a play recorded by the system, only to find that the recording had nothing to do with the intended play. Once trust is lost, it’s hard to rebuild.)
- The icing on the cake, some games did not even have a game clock recorded.
- There was significant overlap between sequential plays in a game. As an example, the data might have recorded one play that spanned 30 seconds, the following play that also spans 30 seconds, and the two plays have 90+% overlapping frames. Isolating plays of interest as well as sequences of interest is thus made impossible without heavy investment in hand annotation of data.
As an aside from an outsider, I’d say it’s pretty clear now why SportVU lost the contract with the NBA given the daunting work required before an analyst can even… well, analyze the data… or know where to look to start.
Despite the friction, the “rocks" of data ended up yielding enough gold dust to recap the project investment as illustrated in the findings section.
Model Architecture
With the data in place, it was finally time to commence model training. Taking inspiration from Word2Vec and embedding projects developed in Tensorflow (e.g., movie sentiment classification), a relatively shallow, simple neural network was developed that would predict the probability a shot goes in and offshoot player embeddings as a byproduct.
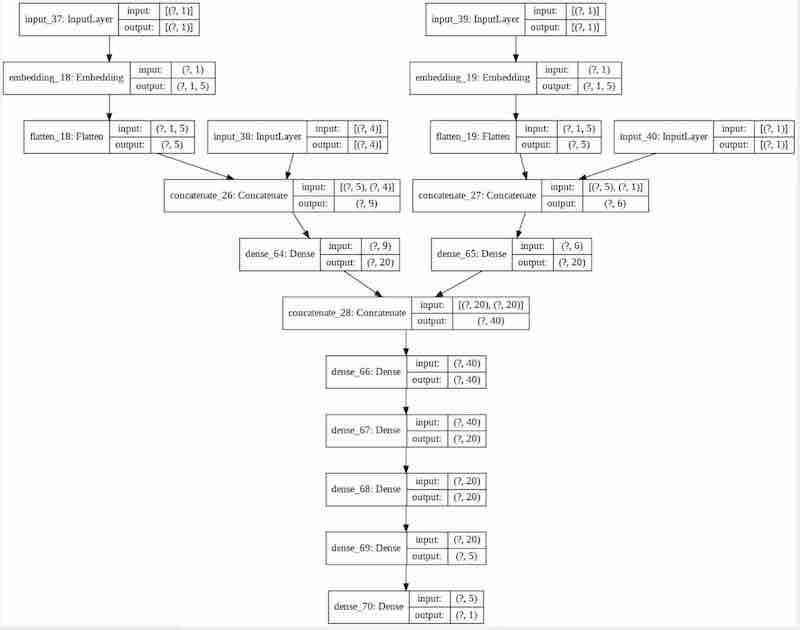
The model architecture above was selected after fairly basic grid searches along available hyperparameters such as number of hidden layers, width of layers, and embedding sizes. Inputs to the model are the location of the player in the act of shooting, time on the shot clock, distance of the nearest defender, distance of the nearest defender from the shooting player, and identity of the shooter/defender. The identities of the shooter and defender become indexes into the embedding layers. These embeddings are then concatenated with the rest of the variables before being scored in a relatively shallow neural network that predicts the probability the shot enters the hoop.
Player Embiiding Visualizations
After training the model to stabilization, the embeddings can be cross-examined in Google’s Embedding Projector. Applying UMAP, the embeddings can be projected into 2D/3D space that is more intuitively perceived by human cognitive capabilities.
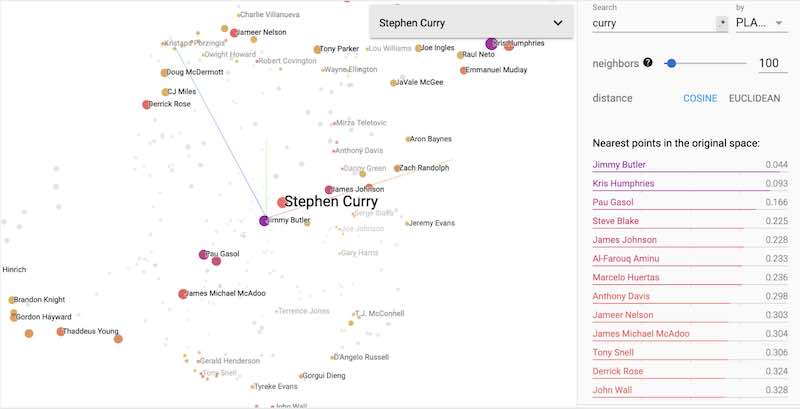
Limitations, Because Nothing is Perfect
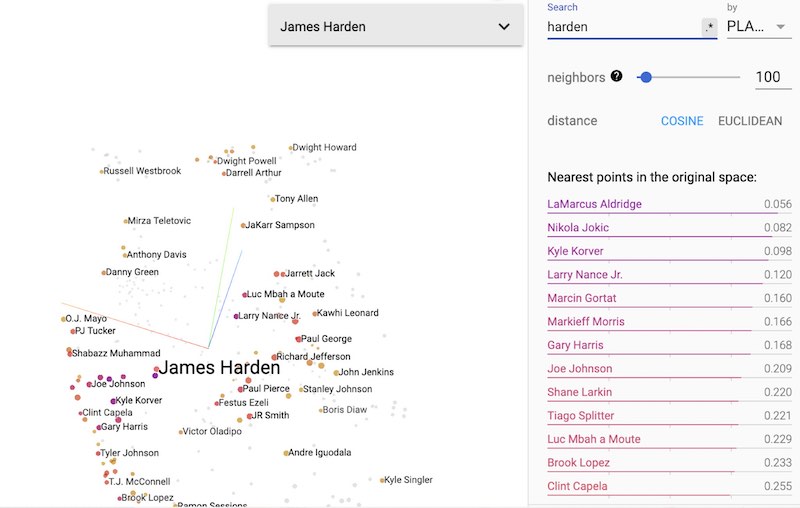
Challenges Separating Players with Sparse Data
One of the biggest challenges with Player Embiidings is how they can sometimes be as highly correlated with the similarities in player style as they are with their lack of overlap. In other words, some players may show as highly similar to players who can only mimic half their game. As an example, consider that some of Harden’s best comparables include those with a great inside game / non-existent outside game like LeMarcus Aldrige or Clint Capella vs others that have a great outside game / non-existent inside game like Kyle Korver. These relationships still hold value given there are some players who have shown brilliance outside their historical data (e.g., Brooke Lopez and Aaron Baynes for 3, James Harden on defense), but need to be taken with a grain of salt in their current form.
Embiidings before Embiid
Despite calling these Embiidings, Embiid was not in the league yet so there are sadly no metrics on him. Another reason for the NBA to open source updated player tracking data.
Improvements, Given All the Limitations
First and foremost, training on more data would set the foundation for all other improvements. The current state of publicly available NBA player tracking data is highly restricted - it's only available for half a season, out-of-date by a few years, suffers from serious time lapses, lacks documentation, and fails to label the occurrence of plays (shots, assists, blocks, steals, etc). I haphazard a guess that the NBA may have shut down the original API not just out of business concern but also publicity / inaccuracy given the numerous challenges experienced during the development of this project.
While there’s a case to be made to keep this information private, like the rapid advancements we’re seeing in the machine learning community, I believe the NBA would significantly benefit from a more open system that encourages experimentation and creativity as well as taps into the power of the public.
- Some forums to make this a reality with NBA sponsorship include open competitions such as Kaggle and controlled cloud environments where data can be controlled and explicitly prevented from being exported.
- Really long term, assuming maturity of the data and model techniques, the NBA could benefit from the development of training camps in partnership with NBA Player Embiidings that require all incoming players to take shots in standard scenarios enough times with enough variation to be able to capture holistic, standard player profiles that complement their game stats profile.
Once the data transitions into a more solid foundation, a few other recommendations include:
- Training the current proof of concept model on more data. This should significantly enhance the generalization of the model by exposing it to more varied situations and providing more data points for non-starter players.
- Training sequential models to capture the state of the game. The current model does not account for the movements leading up to and immediately following the moment the shot is taken. As a result, the model may not account for the increased probability resulting from the shooter drifting away from the defender versus closer, the amount of time the shooter / defender has been in the game, the intensity of the preceding plays, and the complexity of team dynamics (e.g., pick and roll).
- Encouraging separation of players who only overlap in certain aspects of the game. As noted in the limitations section, future iterations could consider outputting multiple classes beyond made shot vs missed shot (e.g., pass, assist, etc) or adding a second loss to the optimization that penalizes the model for clustering players who "overlap in their lack of overlap."
Closing
Given the already lengthy duration of this post, I'll keep this closing short simply noting my sustained enthusiasm for not just the game (again, the game will always refer to basketball) but also its quants. As a fan of both, this project was a way to push boundaries in both fields - developing a fuller perspective on the state of basketball strategy as well as be more informed on the future trajectory of quant basketball. I can’t wait for the new strategies, arbitrage opportunities, and elevated levels of play that Player Embiidings (and their descendants) will come to unlock.
(Due to the aforementioned data limitations, I unfortunately wasn't able to augment my gentlemanly wager among friends with these Player Embiidings. Perhaps next year...)
Methodology and Credits
All source code, training data, and project notes can be found on my Github.
In terms of the raw data, much of the groundwork for not just myself but much of the wider basketball community is attributed to Neil Seward for laying the foundation via open sourcing the NBA Player tracking data from the 2015-2016 season.
Coding was conducted primarily in Tensorflow, PySpark, and Pandas. Visualizations provided via Google Projector and Seaborn.